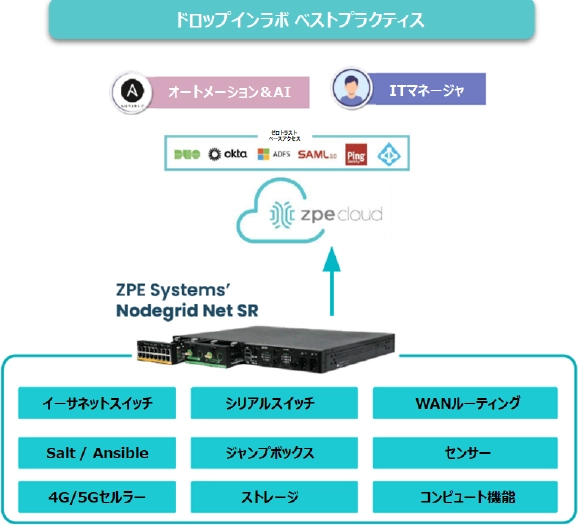
R&D/QAラボにおけるネットワーク検証環境の効率化と管理ベストプラクティスガイド

~ソフトウェアおよび製品開発チームから得た、回復力と効率化の教訓~
ネットワーク管理とプロビジョニングの新たな基準 NetDevOpsプラットフォームの紹介はこちら
お問い合わせはこちら
エグゼクティブサマリー
課題:ラボにおける開発とリリースの遅延
研究開発(R&D)および品質保証(QA)ラボは、イノベーションと製品リリースの要ですが、開発サイクルの遅延という課題に頻繁に直面しています。 エンジニアチームは、不安定なリモートアクセス、コンソールサーバーのフリーズ、手動によるワークフロー、拡張性の乏しい環境への対応に多くの時間を費やしており、これが市場投入(Time-to-Market)の遅れにつながっています。
既存ソリューションの限界:従来のコンソールサーバーではラボ環境に対応できない
ローカルでのサーバー運用を想定した従来のコンソールサーバーは、現代のラボ環境の負荷に耐えられません。複数ユーザー同時接続時のシステムクラッシュ、USB/IPMI接続のために追加デバイスが必要になることによる機材の乱立、自動化/AIテスト機能の欠如、さらにデータバッファ容量不足によるテストログの損失といった問題が、頻繁なダウンタイムやインフラの複雑化、開発の遅延を引き起こしています。
解決策:高密度・インテルCPU搭載 Nodegrid シリアルコンソール
ZPE Systems の Nodegrid デバイスは、R&D/QAラボ向けに専用設計されています。インテル製マルチコアCPUと大容量メモリの搭載により遅延を解消し、100以上の高性能セッションの同時接続をサポートします。 Nodegridはシリアル、USB、イーサネット、IPMIインターフェースを集約することでインフラの乱立(スプロール)を解消します。また、Ansible等のツールによるワークフローの自動化、20,000行のポートバッファによるテストデータ保持、さらにセキュアな第3世代アウトオブバンド(OOB)管理機能により、トラブルシューティングのための現地駆け付けを不要にします。
導入メリットとROI
- 市場投入までの期間短縮: 安定した同時リモートアクセスと自動化により、テストと開発サイクルを加速。
- TCO(総所有コスト)の削減: シリアル、USB、イーサネット、IPMIを1つの高密度かつスケーラブルなプラットフォームに統合。
- 生産性の向上: 自動化、ログ記録、直感的なセッション制御を実現。
- ラボ訪問回数の削減: セキュアなリモートネットワークアクセス(OOB)、リモート再起動、大容量バッファによるログ損失防止により、物理的な現地対応を最小化。
- セキュリティとコンプライアンスの強化: 集中型アクセス制御、セッションログ記録、SSO(シングルサインオン)統合を提供。
現代の研究開発要件が従来のラボインフラを圧倒している現状
R&D/QAラボでは、分散したチーム、多様なハードウェア構成、そして迅速なテスト反復を、時差を超えてサポートする必要があります。マッキンゼー(McKinsey & Company)の調査によれば、アジャイルで効率化されたR&Dプロセスを採用する組織は、市場投入までの時間を少なくとも40%短縮し、競争優位性を確立できるとしています。
しかし、低負荷のローカル管理しか想定していない従来のコンソールサーバーやアクセスツールでは現在の負荷に耐えきれません。その結果、チームは対面での調整や手動プロセスに時間を浪費し、貴重なテストデータを失うことになります。主な問題は以下の3点です。
 画像:デバイスの乱立により、ラボは専用機器と絡み合ったケーブルの混乱状態に陥っている。
画像:デバイスの乱立により、ラボは専用機器と絡み合ったケーブルの混乱状態に陥っている。
- システムクラッシュ
従来のコンソールサーバーの多くは単一ユーザーによる制御を前提に設計されています。複数のエンジニアが同時にテスト機器へアクセスしようとすると、セッションのフリーズや機器の応答停止が発生し、システムがクラッシュします。復旧待ちの間、チームの生産性は完全に停止します。 - 機材の乱立(Device Sprawl)
R&Dラボにはサーバー、USB周辺機器、ネットワーク機器、IoTデバイス、環境制御装置などが溢れています。これらをサポートするために、従来はインターフェースごとに異なるコンソールサーバーが必要でした。その結果、機材が乱立し、ケーブルが複雑に絡まり合い、コストが増大するだけでなく、テスト対象機器のためのラックスペースが圧迫されます。 - 手動作業による非効率
多くの従来型製品はスクリプト機能を持たず、バッファ容量も小さく、永続的なログ機能もありません。エンジニアは手動でログインし、テストを実行し、ログを収集しなければならず、人的ミスやデバッグデータの欠落を招きます。また、テスト中にデバイスがクラッシュした場合、その結果データ自体が消失するリスクもあります。
課題解決のための3つのベストプラクティス
これらの問題を解決するために、チームは以下の3つの問いに取り組む必要があります。
- システムダウンを防ぎ、チームが効率的に同時作業できるようにするにはどうすればよいか?
- 機材や複雑さを増やさずに、ラボ環境を拡張するにはどうすればよいか?
- 定型作業や現地トラブルシューティングの工数を削減するにはどうすればよいか?
1. 同時接続時のシステム安定性の確保
【課題】
現代の開発/品管チームは世界中に分散していますが、ラボ設備は依然として「ローカル・単一ユーザー」向けです。従来のコンソールサーバーは「障害発生時の緊急用(Break-Fix)」として設計されており、日常的な高負荷利用やマルチユーザーアクセスを想定していません。低速なCPUと少量のRAMでは、頻繁なフリーズやクラッシュが発生します。
【ベストプラクティス】
- 同時セッション対応のプラットフォームを採用する: 100人以上の同時ユーザーをパフォーマンス低下なくサポートできること。
- ID管理の統合: SSO、LDAP、RADIUSを統合し、RBAC(ロールベースアクセス制御)によるセキュアな環境を構築する。
- 生産性向上機能: ブラウザベースのアクセスや、コードのコピー&ペースト機能を活用し、ワークフローを高速化する。
【ZPE Nodegridによる解決策】
Nodegridは最大8コアのインテルCPUと大容量RAM(8-32GB)を搭載し、100以上のアクティブセッションを容易に処理します。また、CLIまたはWeb GUI経由で、物理接続しているかのような操作感を提供し、統合クリップボード機能によりコマンド入力の手間を省きます。
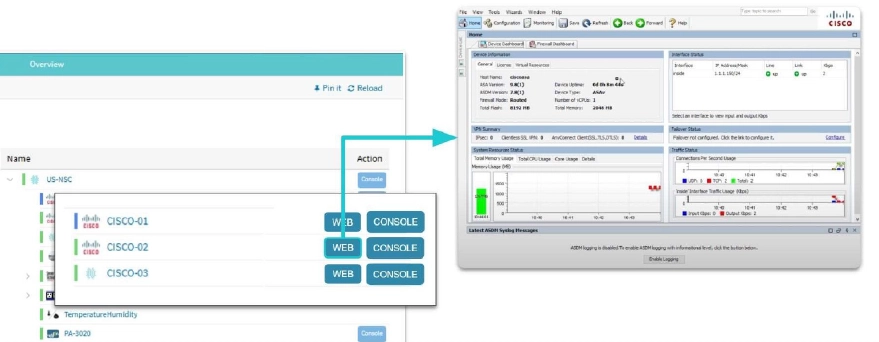
図:ZPE SystemsのNodegridは、研究開発チームに実験室インフラの集中管理ビューを提供します。ウェブブラウザを使用し、すべてのデバイスを確認し、CLIまたはウェブGUI経由で個別アクセスが可能です。NodegridのマルチコアIntel CPUと8GB以上のRAMは、100以上の同時セッションをサポートし、チームの作業速度を低下させません。
2. 機材の乱立(Device Sprawl)を防ぐインフラ統合
【課題】
ラボにはシリアル、USB、イーサネット、IPMI対応機器が混在しており、従来はそれぞれに専用の管理デバイスが必要でした。これが「機材の乱立(デバイススプロール)」を招き、管理の複雑化とラックスペースの浪費を引き起こしています。
【ベストプラクティス】
- マルチインターフェース対応: シリアル、USB、イーサネット、IPMIを1台のアプライアンスで収容する。
- 高密度ソリューション: ラックスペースを節約するため、高密度ポート(48~96ポート)のモデルを選択する。
- 管理の集約: 制御を集中化することで、デバイスアクセスと配線を簡素化する。
【ZPE Nodegridによる解決策】
Nodegridは1台でシリアル、USB、イーサネット、IPMIデバイスの接続を実現します。特に Nodegrid Net SR はモジュール交換式であり、環境に合わせてインターフェースを構成可能です。1RUサイズで最大96ポートをサポートするため、ラックスペースと配線の複雑さを劇的に削減します。

3. 自動化とリモート対応による工数削減
【課題】
手動によるテストプロセスは時間がかかり、ログの取りこぼしや人的ミスが発生します。従来のコンソールサーバーはバッファ(通常256KB-1MB程度)が小さく、長時間のテストログが溢れて消えてしまうことがあります。また、ネットワーク障害時にOOB(アウトオブバンド)アクセス手段がない場合、現地での再起動作業が必要になります。
【ベストプラクティス】
- 自動化の導入: スクリプトを用いてプロビジョニング、テスト実行、ログ収集を自動化する。
- 大容量バッファ: データ損失を防ぐため、ポート単位で大容量バッファ(10,000〜20,000行)を持つ製品を選ぶ。
- 完全なリモート管理: 24時間365日の継続性確保のため、永続的なログ記録とOOB経由の再起動手段を確保する。
【ZPE Nodegridによる解決策】
NodegridはPython、Bash、Ansibleなどとの自動化を統合するフレームワークを提供します。また、ポートあたり最大20,000行のバッファにより、長時間テストのログも完全に保持します。万が一の障害時には、統合されたOOBアクセス機能により、メインネットワークがダウンしていてもリモートから電源リサイクル(再起動)やトラブルシューティングが可能です。
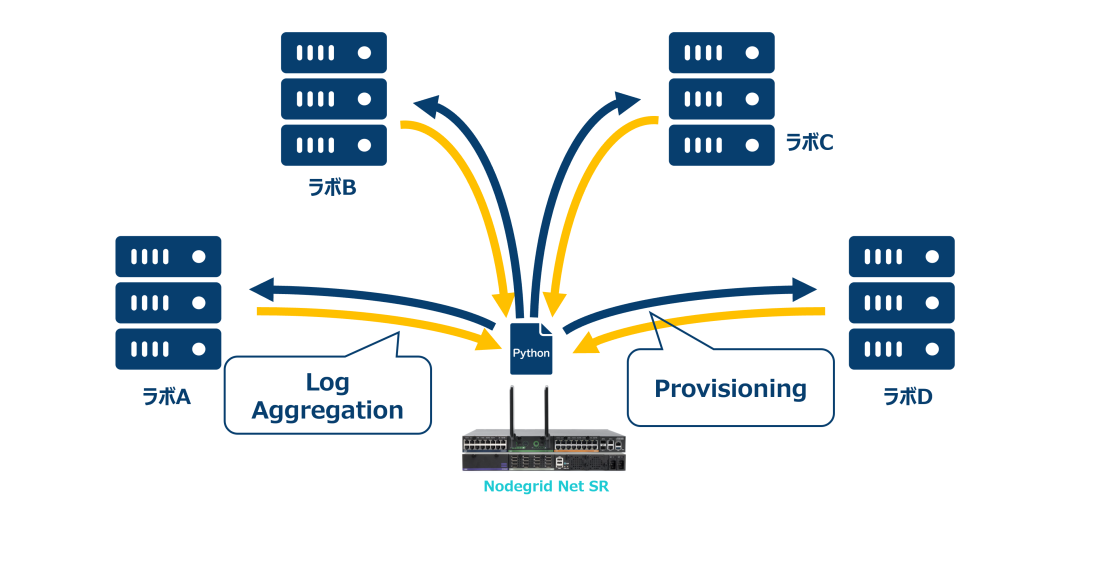
現代的なR&D/QAラボ管理のブループリント(青写真)
高速でスケーラブル、かつ耐障害性の高い検証環境を実現するための導入ステップ:
- すべてのラボ機器を物理的にNodegridに接続する サーバー、PDU、ネットワーク機器、IoTハードウェアなどをNodegridに集約します。ベンダーやインターフェースの種類(シリアル、USB、イーサネット)に関わらず、すべての資産に対する集中管理とログ記録を可能にします。
- 自動化ツールと開発ツールの統合 Nodegridのオープンアーキテクチャを活用し、CI/CDパイプライン、Ansible、Python、REST APIと連携させます。再起動、テスト実行、ログ収集を自動化し、手動作業を排除してテストサイクルを短縮します。
- アクセスと管理制御の集中化 全ラボ環境におけるコンソールアクセス、監視、デバッグを統一します。RBAC(ロールベースアクセス制御)、監査ログ、OOB管理により、グローバルに分散したチームに対し、セキュアで高性能なワークフローを提供します。