GPUの電力を「見える化」する:AIベンダが取り組むべき次世代の環境ガバナンス

ラック単位やPDU単位の電力監視だけで、本当にデータセンターの無駄を省けていると言えるのでしょうか。AIワークロード特有の電力スパイクや、高性能GPUが発する膨大な熱を適切に管理するには、従来の「ファシリティ主体のDCIM」ではデータの粒度が不足しています 2。今後のデータセンター運用に求められるのは、サーバー内部のCPUやGPU、さらには冷却コンポーネント単位でのリアルタイムなテレメトリ収集です。本稿では、特定のベンダーに依存せず、ITデバイスそのものの挙動を詳細に監視・制御することで、インフラの真の効率を引き出すAMI DCMの技術的優位性と、それがもたらす運用変革について掘り下げてまいります。
1. AIインフラが抱える膨大な計算量と電力消費のジレンマ
生成AI(Generative AI)の爆発的な普及は、デジタル社会に計り知れない恩恵をもたらす一方で、データセンターのインフラ設計に根本的な変革を迫っています。かつてない計算量を支えるためには、これまでの汎用サーバーとは比較にならないほどの電力が投入されなければならないためです。
1.1. 2030年に向けた電力需要の爆発的増加の背景
ガートナーの予測によれば、データセンターの電力消費量は2025年の448テラワット時(TWh)から、2030年には980TWhへと、わずか5年で2倍以上に増加するとされています。この急激な伸びを牽引しているのがAI最適化サーバーです。2030年までに、AI最適化サーバーがデータセンター全体の電力使用量の44%を占める見込みであり、追加される電力需要の64%がAI関連のコンピューティングに起因すると考えられています。これは、データセンター事業者が今後、AIへの対応を抜きにしては電力管理や持続可能性を語れないフェーズに入ったことを示唆しています。
1.2. 高密度コンピューティングと物理的制約の深刻化
AIインフラの進化は、物理的な設置環境にも多大な影響を及ぼしています。ラックあたりの平均電力密度は、数年前の16kWから27kWへと劇的に上昇しており、将来的にはNVIDIA Blackwellプラットフォーム(GB200 NVL72)のように、1ラックで120kW、さらにはメガワット級のシステムも視野に入ってきています。このような高密度環境では、従来の空冷システムだけでは熱を処理しきれず、液冷(Liquid Cooling)への移行が加速しています。しかし、冷却システムが高度化・複雑化すればするほど、その運用に必要なエネルギーの最適化も難しくなり、管理の難易度は増す一方ではないでしょうか。
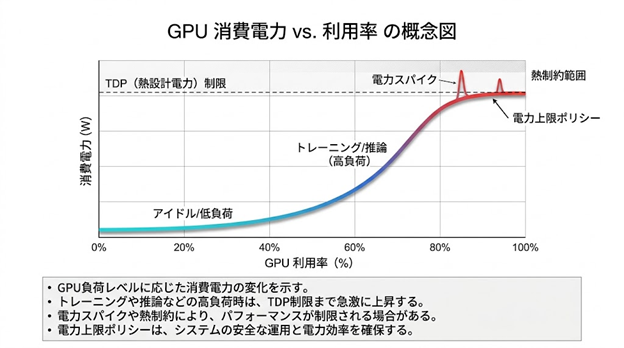
1.3. 計算リソースの効率的配分と電力スパイク
AIの学習や推論プロセスでは、特定の瞬間に電力が急増する「電力スパイク」が発生しやすいという特性があります。施設全体の大まかな電力管理では、こうした細かな変動を捉えることができず、結果として予備電力の過剰確保や、ブレーカー遮断を恐れたリソースの過小利用を招いています。持続可能な運用のためには、デバイス単位での「電力量の予見性」を高めることが不可欠です。
|
項目 |
2025年予測 |
2030年予測 |
|
世界全体のDC電力消費量 |
448 TWh |
980 TWh |
|
AI最適化サーバーの消費割合 |
21% |
44% |
|
DC追加電力需要に占めるAIの割合 |
– |
64% |
2. AIベンダに求められるCSRとカーボンニュートラルへの社会的責任
AI技術を提供するベンダーやデータセンター事業者にとって、環境負荷への対策はもはや「任意の取り組み」ではありません。企業のガバナンスや社会的信用、さらには法的コンプライアンスに直結する、喫緊の経営課題となっています。
2.1. 脱炭素化への国際的な圧力と国内法規制の動向
世界的なカーボンニュートラルへの潮流の中、日本国内でも法規制の整備が急速に進んでいます。資源エネルギー庁の「ベンチマーク制度」では、2024年度からデータセンター業が対象に含まれ、エネルギー使用効率を示す指標であるPUE(Power Usage Effectiveness)の目標値が「1.4以下」に設定されました。年間のエネルギー使用量が原油換算で1,500kL以上の事業者には、毎年の報告義務が課されており、省エネへの取り組みが遅れている事業者には、改善を促す厳しい指導や社名公表の可能性も含まれています。
2.2. カーボンフットプリントの透明性と「グリーンAI」への期待
企業のサステナビリティレポート(ESG報告)において、自社の事業活動がどれだけのCO2を排出しているかを示す「カーボンフットプリント(CFP)」の開示は、投資家や顧客からの信頼を得るための必須条件となっています。AIを利用するエンドユーザーも、より環境負荷の低い「グリーンなAI」を選択する傾向が強まっており、サプライチェーン全体での排出量把握(スコープ3)が求められています。こうした背景から、データセンター内の各デバイスが具体的にどれだけの電力を消費し、どれだけの炭素を排出しているかを正確に証明する「エビデンス」の重要性が、かつてないほど高まっているのです。
2.3. 社会的影響(CSR)としての電力消費対策
データセンターが地域社会の電力を大量に消費することは、時として電力網への負荷増大として批判の対象となります。企業がこの課題に誠実に向き合い、最新の管理技術を導入して消費電力を最小化することは、CSR(企業の社会的責任)の観点からも極めて重要です。単に「再エネを買う」だけでなく、「自社のインフラがいかに効率的か」をデータで示すことが、長期的な事業継続を可能にします。
3. なぜ従来の電源管理主体「DCIM」ではカーボンオフセットに不十分なのか
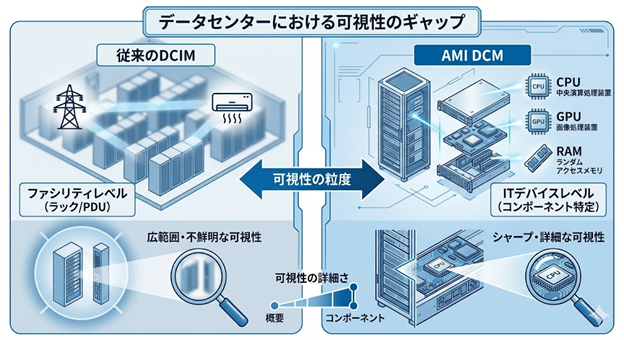
これまで多くのデータセンターで導入されてきたDCIM(Data Center Infrastructure Management)は、主に施設(ファシリティ)側の管理を目的としていました。しかし、AI時代の精緻なカーボン管理においては、そのアプローチに限界が露呈しつつあります。
3.1. 「施設」と「ITデバイス」の間に存在する視覚のギャップ
従来のDCIMは、主にPDU(電源タップ)、UPS(無停電電源装置)、空調機、漏水センサーなどの物理インフラの稼働状況を監視することに重きを置いてきました。この手法では、ラック単位の電力使用量は把握できても、「そのラックの中で、どのサーバーが、どのGPUが、具体的に何ワット消費しているか」という詳細なデータを得ることは困難です。AIのワークロードは極めて動的であり、サーバー内の各コンポーネントが不規則に電力を消費するため、ファシリティ側のデータだけでは「どこに無駄があるのか」を突き止めることができません。
3.2. カーボンオフセットに求められる「実測値」の信頼性
カーボンオフセット(温室効果ガス排出枠の購入や削減証明)を実施する際、企業は排出量を算出しますが、その根拠となるデータが「定格電力からの推計値」や「ラック全体の平均値」であっては、昨今の厳しい監査基準には耐えられません。グリーンウォッシュ(見せかけの環境配慮)との批判を免れるためには、デバイスレベルでのリアルタイムな実測値が不可欠です。従来のDCIMが提供する「大まかなデータ」では、厳格なサステナビリティ基準を満たすための高品質なエビデンスとしては不十分であると言わざるを得ないのではないでしょうか。
3.3. 冷却最適化への限界
多くのDCIMは、通路の温度センサーや空調機の吹き出し温度を監視しますが、サーバー内部のCPUやGPUのジャンクション温度までは把握していません。その結果、安全マージンを過剰に取った「過剰冷却」が発生し、多大なエネルギーが浪費されています。ITデバイスそのものからのテレメトリ(遠隔測定データ)を取得できないDCIMでは、冷却エネルギーを究極まで削ぎ落とすことは不可能なのです。
|
比較項目 |
従来のDCIM |
ITデバイス中心の管理 (AMI DCM) |
|
主な監視対象 |
UPS, PDU, 空調, 物理セキュリティ |
サーバー, GPU, CPU, ストレージ, ネットワーク |
|
データの取得元 |
外部センサー, スマートPDU |
BMC (Redfish, IPMI), CPU/GPU内部テレメトリ |
|
管理の粒度 |
施設全体、またはラック単位 |
デバイス単位、コンポーネント単位 |
|
AIインフラ対応 |
不十分(GPUの負荷率等は不明) |
高度(NVIDIA/AMD GPUの利用率、電力を監視) |
|
環境報告への寄与 |
推計値ベースの報告 |
実測値ベースの精密なカーボン証明 |
4. ITデバイス中心の次世代管理「AMI DCM」の全体像と優位性
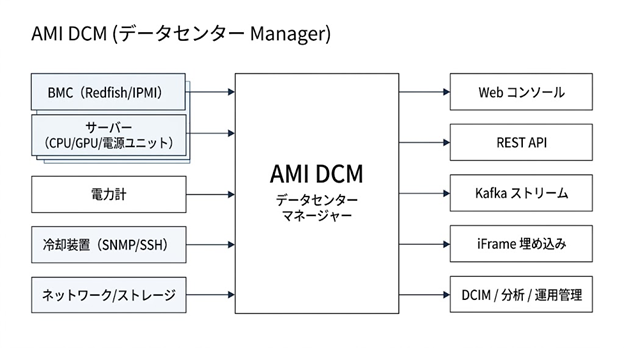
こうした課題を解決するために開発されたのが、AMI(American Megatrends International)社の「Data Center Manager (DCM)」です。AMI DCMは、従来のファシリティ管理の枠を超え、ITデバイスそのものの挙動を深掘りする「ITデバイス中心(IT-Device Centric)」のアプローチを採用しています。
4.1. アウトオブバンド監視による非侵襲的なデータ収集
AMI DCMの最大の特徴の一つは、監視対象のサーバーにエージェントソフトを導入する必要がない「アウトオブバンド(Out-of-band)」方式である点です。IPMI、Redfish、SNMP、SSHといった標準的なプロトコルを使用し、サーバーのマザーボード上に搭載された管理用チップ(BMC: Baseboard Management Controller)から直接テレメトリデータを取得します。これにより、OSやアプリケーションに一切の負荷をかけることなく、リアルタイムで詳細な健康状態、電力消費、温度情報を収集することが可能です。本番環境への影響を懸念するデータセンター担当者にとっても、非常に導入しやすい仕組みと言えます。
4.2. ベンダーに依存しない「Vendor Agnostic」な設計
特定のサーバーベンダーやハードウェアメーカーのツールに依存すると、混在環境(ヘテロジニアス環境)での管理が極端に煩雑になります。AMI DCMは、HP、Dell、Lenovo、Supermicroといった主要ベンダーはもちろん、AMDベースのサーバーやARMベースのAmpereプロセッサなど、多種多様なアーキテクチャを横断して一元管理できる設計となっています。これにより、ユーザーは最新かつ最適なハードウェアを自由に選択しつつ、運用管理だけは一元化された効率的なプラットフォームを維持し続けることができるのです。
4.3. 最大60,000ノードを支える圧倒的なスケーラビリティ
AMI DCMは、小規模な構成から大規模なハイパースケールデータセンターまで対応できる高い拡張性を備えています。1つのソフトウェアインスタンスで最大60,000ノードを統合管理でき、複数の拠点に分散したインフラも「シングル・ペイン・オブ・グラス(単一の監視画面)」で可視化します。このスケーラビリティこそが、急成長を続けるAIサービスプロバイダーや大手クラウド事業者に選ばれる理由の一つです。
5. GPUの電力監視とベンダー非依存(Vendor Agnostic)がもたらす価値
AIインフラの心臓部であるGPUの管理において、AMI DCMは他のツールとは一線を画す強力な機能を備えています。特にAIワークロードの最適化と電力管理を両立させる上で、以下の機能が重要な役割を果たします。
5.1. NVIDIA GB200を含む最新GPUへの深い洞察
AMI DCMは、NVIDIAの最新プラットフォームであるBlackwell(GB200 NVL72)をはじめ、主要なデータセンター向けGPUを詳細にサポートしています。
- リアルタイム監視: GPUの電力消費、利用率(Utilization)、温度、メモリエラー(ECC)の状態、さらにはファンの回転速度までを秒単位で把握します。
- 高度な制御(Power Capping): サーバーやGPUに対して、ソフトウェアから直接電力制限(パワーキャッピング)をかけることができます。これにより、ピーク時の電力消費を抑制し、契約電力内での安定稼働や、予期せぬ停電リスクの回避が可能になります。
5.2. AIワークロードの「真の効率」を可視化
単に「動いているか」だけでなく、そのGPUが「いかに効率的に計算を行っているか」を分析することが可能です。低負荷なGPUを特定し、ワークロードを特定のサーバーへ集約(コンソリデーション)することで、不要なデバイスの電源をオフにし、大幅な省エネを実現する意思決定を支援します。
5.3. 予兆検知によるダウンタイムの回避
AIの学習は数週間から数ヶ月に及ぶこともあり、その途中でハードウェア故障が発生すると多大な損害を招きます。AMI DCMの予測分析機能は、電力や温度の異常なトレンドから、故障が発生する前にアラートを発報します。これにより、計画的なメンテナンスが可能となり、インフラの信頼性を飛躍的に高めることができます。
|
管理可能なGPUタスク |
内容 |
|
ヘルス監視 |
GPUの健康状態とハードウェア故障の予兆をリアルタイムで検知 |
|
電力制限 |
指定した閾値を超えないようにGPUの消費電力を自動調整 |
|
ECC制御 |
エラー訂正コード(ECC)の有効化/無効化やエラー件数の集計 |
|
診断・リセット |
リモートからの診断実行、およびGPUのソフトリセット |
6. 監視データの活用によるインフラ最適化とコスト削減(ROI・事例)
AMI DCMを導入する究極の目的は、単なる「監視」に留まりません。収集された膨大なデータに基づき、インフラの最適化を断行することで、劇的なコスト削減(OpEx/CapExの削減)を実現することにあります。
6.1. 「ゾンビサーバー」の特定とリソースの集約によるROI
多くのデータセンターには、電源は入っているものの、実際には何の計算処理も行っていない「ゾンビサーバー(Comatose Servers)」が一定数存在しています。AMI DCMは、CPU/GPUの利用率と電力消費を長期間にわたって紐づけて分析することで、これらの無駄なサーバーを確実にあぶり出します。 これらを停止、または統合することで、サーバー自体の電力コストだけでなく、その周囲を冷やすための空調コストも一挙に削減でき、短期間での投資回収が可能になります。
6.2. 冷却効率の最適化と過剰冷却の解消
データセンターのエネルギー消費の約30〜40%を占めると言われる空調設備ですが、多くの現場では「万が一の故障」を恐れて、必要以上に冷やしすぎています。AMI DCMは、各ラックや各デバイスの温度を立体的にマッピング(サーマルマップ)し、局所的なホットスポットを特定すると同時に、冷却に余裕があるエリアを見極めます。 このデータをBMS(建物管理システム)と連携させることで、空調の設定温度を安全に引き上げることができ、多大な電力削減に繋がります。
6.3. 導入企業の成功事例:CO2削減とコスト削減の両立
実際のある大規模データセンターにおけるAMI DCMの導入成果は、その有効性を雄弁に物語っています。
- 電力消費の15%削減: リアルタイム監視と電力最適化(パワーキャッピングやリソース集約)により、不要な消費を徹底排除しました。
- カーボンフットプリントの30%削減: 精緻なデータに基づく運用改善により、年間CO2排出量を大幅に抑制することに成功しました。
7. ベンチマーク制度準拠とカーボンフットプリント証明の自動化
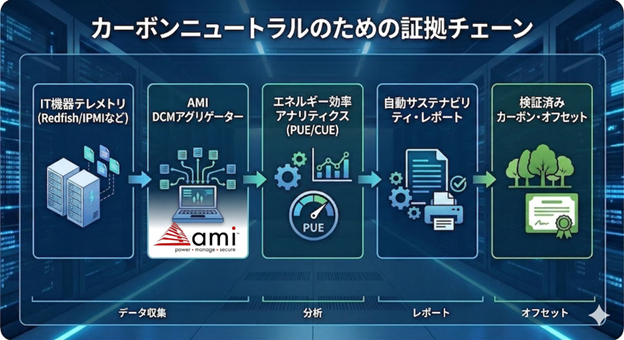
サステナビリティ担当者が直面する最大の課題は、信頼性の高い「報告書」を作成するためのデータ収集作業の煩雑さではないでしょうか。AMI DCMは、この業務を劇的に効率化します。
7.1. 日本の省エネ法・ベンチマーク報告の自動化
資源エネルギー庁に提出するベンチマーク報告書では、以下のPUEの計算が求められます。
ここで、(施設全体の消費電力)は受電設備で計測可能ですが、(IT機器そのものの消費電力)を正確に把握するのは非常に困難です。多くの事業者が「ラック全体の電力」や「分電盤の値」で代用していますが、そこにはネットワークスイッチや不要な周辺機器の電力も含まれ、本来のIT効率を反映していません。 AMI DCMは、個々のサーバーから直接「IT機器そのもの」の消費電力を吸い上げるため、極めて精度の高いPUE算出を可能にします。7.2. カーボンフットプリント(CFP)証明の自動生成
AMI DCMは、収集した電力データに排出係数を掛け合わせ、デバイス単位、ラック単位、あるいはサービス(テナント)単位でのCO2排出量をリアルタイムで算出します。このデータはRESTful APIやApache Kafkaを介して外部システムへストリーミング配信できるため、企業のサステナビリティポータルや、顧客向けのダッシュボードへ直接反映させることが可能です。 推計に基づく「説得力の弱い報告」から、実測に基づく「信頼される報告」への転換は、企業のブランド価値を決定づける要因となります。
7.3. ガバナンスとしてのエビデンス保持
法規制や監査への対応において、「いつ、どのデバイスが、どれだけの電力を消費したか」というヒストリカルデータ(履歴)を保持していることは、強力な武器となります。AMI DCMは長期的なトレンド分析をサポートしており、過去数年分にわたるエネルギー使用状況をいつでも即座にレポートとして出力できるため、監査対応の工数を大幅に削減できます。
よくある質問(Q&A)
Q1:既存のDCIMや建物管理システム(BMS)を導入済みですが、さらにAMI DCMを導入するメリットはどこにありますか?
A: 既存のDCIMやBMSは主に「施設側(電源、空調、セキュリティ)」の物理インフラを守るためのものです。一方でAMI DCMは、ITデバイスそのものの「健康状態、負荷、内蔵コンポーネントの電力」を可視化することに特化しています。AMI DCMを併用することで、例えば「サーバーの計算負荷に合わせて空調の出力を調整する」といった、施設とITの枠を超えた高度な最適化が可能になり、単体のDCIMでは到達できない領域の省エネを実現できます。
Q2:マルチベンダー環境で、NVIDIA GPUやAMD、ARMなど様々な機器が混在していますが、本当に一括で監視可能ですか?
A: はい、可能です。AMI DCMの最大の強みは、ハードウェアのベンダーに依存しない「ベンダーアグノスティック」な設計にあります。IPMIやRedfishといった業界標準規格に準拠しているデバイスであれば、メーカーを問わず同一のダッシュボードで一括管理できます。実際に、HPE、Cisco、Dell、Supermicro、Wiwynnなどの最新サーバーから、主要なPDU、ネットワークスイッチまで、広範なサポートが実証されています。
Q3:詳細な監視ツールを導入することで、設定や管理の手間(運用コスト)がかえって増えませんか?
A: むしろ運用の自動化により、トータルのコストは削減されます。AMI DCMは「アウトオブバンド方式」を採用しているため、管理対象のサーバーにエージェントをインストール・更新する手間がありません。また、自動での資産発見(Asset Discovery)機能や、AIチャットボット「AMILiA」による対話形式の問い合わせ対応など、最新のUI/UXによって管理者の負担を最小限に抑える工夫がなされています。削減される電力コストと運用工数を考えれば、非常に高いROIが期待できるソリューションです。
まとめ
AI時代におけるデータセンター運営は、爆発的な電力需要への対応と、厳格化する環境規制への準拠という、二正面作戦を強いられています。本レポートで詳述した通り、従来のファシリティ主体のDCIMでは、AIワークロードが引き起こす微細な電力変動やコンポーネントレベルの熱課題に対応しきれず、信頼性の高いカーボンオフセットのエビデンスを構築することも困難です。AMI DCMは、ITデバイスレベルでの詳細なテレメトリ収集を通じて、インフラの透明性を飛躍的に高めます。マルチベンダー対応、最新GPUのフルサポート、そして実測に基づく報告業務の自動化というAMI DCM独自の強みは、データセンター事業者が持続可能性と経済性を両立させるための、最も現実的かつ強力な解決策となるはずです。