VPNとジャンプホストがMSPの規模拡大において機能不全に陥る理由、そしてその解決策

MSP(マネージドサービスプロバイダー)やマネージドネットワークサービスプロバイダーは、日々の業務においてリモートアクセスに依存しています。エンジニアは、数十から数百に及ぶ顧客環境にまたがるファイアウォール、ルーター、スイッチ、ハイパーバイザー、サーバーに接続しています。これは運用の中核となる機能であり、これなしではMSPは存在し得ないでしょう。
リモートアクセスモデルの基盤は、多くのプロバイダーにとっておなじみのものです。それは、VPNトンネルとジャンプホストまたはバスティオンサーバー(踏み台サーバー)を組み合わせたものです。これらのツールにより、エンジニアは一元化された環境にログインし、顧客ネットワーク全体にわたるインフラストラクチャにアクセスできます。顧客数が少ないうちは、このモデルは比較的うまく機能します。しかし、MSPが拠点を増やし、顧客基盤を拡大し、より多くのインフラストラクチャを展開するにつれて、この従来のモデルは管理不能な状態になってしまいます。
実際の障害シナリオにおいて、VPNやジャンプホストのアーキテクチャがどのように機能するのかを見ていくことで、その理由を探ってみましょう。
お問い合わせはこちら
MSPのリモートアクセスモデル
ほとんどのMSP/MNS環境では、階層化されたリモートアクセスアーキテクチャが採用されています。エンジニアは、MSPまたは顧客環境のいずれかでホストされているVPNゲートウェイを介して接続します。認証が完了すると、ネットワークインフラへの管理されたエントリポイントとして機能する内部のジャンプホストまたはバスティオンサーバーに到達します。
このジャンプホスト/バスティオンサーバーから、エンジニアは以下のインフラストラクチャにアクセスします。
- エッジルーターおよびファイアウォール
- コアスイッチ
- ハイパーバイザーおよびストレージシステム
- 監視サーバー
- IDサービス
- 仮想インフラストラクチャプラットフォーム(VMware、Microsoft Hyper-Vなど)
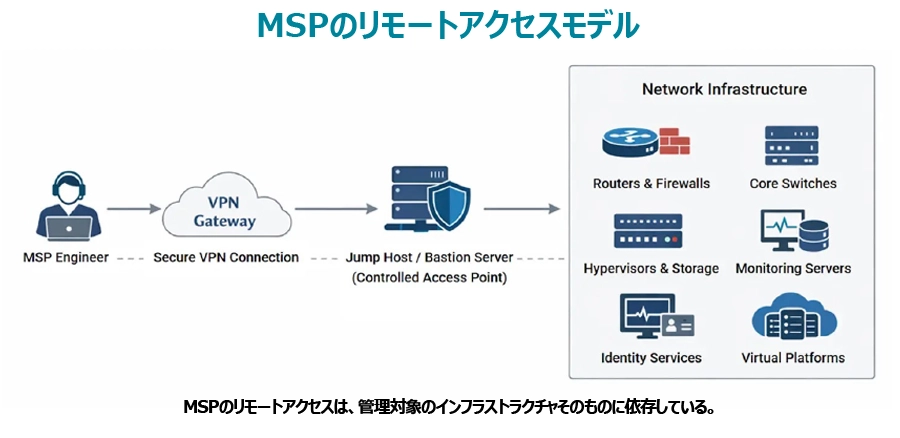
このアーキテクチャにはいくつかの利点があります。特定の顧客環境に対するアクセス制御を一元化し、認証情報の管理をある程度簡素化するとともに、エンジニアが機密性の高いシステムにアクセスする前に、セキュリティチームが認証ポリシーを適用できるようにできます。
しかし、リモートアクセスは、本番環境のインフラ全体が稼働し続けているという前提に立っています。
もしそれが機能しなくなったらどうなるでしょう?
インバンド管理が機能しなくなったとき:よくある障害シナリオ
VPNやジャンプホストは完全にインバンドで動作するため、管理対象であるネットワークインフラそのものに依存しています。
以前のMSP記事では、この依存関係について詳しく解説しました。要するに、障害が発生するとインバンド管理が遮断され、些細な問題がMSPの利益を圧迫する大規模なサービス停止へと発展してしまうのです。そして、発生し得る障害は多岐にわたります。ここでは、長時間のサービス停止や現場対応を招く代表的なシナリオをいくつか紹介します:
- ルーティング障害により、エンジニアと環境との間の経路が完全に遮断される可能性があります。BGPの設定ミス、OSPFの障害、あるいはファームウェアの更新失敗さえも、VPNセッションを瞬時に切断する可能性があります。問題を引き起こしているデバイスは稼働しているかもしれませんが、アクセスできないため、エンジニアは修正できません。
- ファイアウォールのポリシー設定ミスは、管理トラフィックをブロックすることがよくあります。1つのルールの誤適用や自動更新だけで、内部システムへのアクセスが遮断される可能性があります。ファイアウォールはオンラインですが到達不能な状態となり、現場での支援なしには単純なルール変更さえ不可能になります。
- WANやISPの障害が発生すると、リモート接続は完全に遮断されます。内部ネットワークが機能していても、環境外のエンジニアはアクセスできません。本来なら迅速に解決できるはずの問題が、現場への出張対応を必要とする事態に発展します。
- 認証の失敗により、システム自体は正常であっても、エンジニアがジャンプホストにアクセスできなくなる場合があります。Active DirectoryやLDAPなどのIDサービスが利用できない場合、ログイン試行は失敗し、トラブルシューティングは停止してしまいます。
- DNSや証明書の検証に関する問題など、中核となるサービスの障害も、間接的にアクセスを遮断する原因となり得ます。デバイス自体はまだアクセス可能であっても、それらに接続するために使用するツールが機能しなくなる場合があります。
これらのシナリオについては別の記事でさらに詳しく解説しますが、そのパターンは明らかです。インフラストラクチャが稼働している場合でも、最も重要な局面において、エンジニアはインフラにアクセスできなくなってしまうのです。
MSPの規模拡大に伴い問題が深刻化する理由
このインバンド型リモートアクセスモデルの脆弱性はひとまず置いておき、純粋に「規模」について考えてみましょう。数十もの顧客環境を管理する場合、それぞれにVPNゲートウェイ、ファイアウォール/ポリシー、ルーティングドメイン、ID連携などが追加されます。
その単純なリモートアクセスモデルは、複数のネットワークにまたがるVPNトンネル、ジャンプホスト、バスティオンサーバー、認証システムからなる、高度に分散化されたパッチワークへと変貌します。これがスケールしない理由は、想像に難くないでしょう。
アクセスの断片化
エンジニアが単一の管理環境に接続することはほとんどありません(もちろん、ZPE Cloudを使用している場合は別ですが)。その代わりに、顧客ごとに個別のアクセス経路を維持しており、その様子は次のようになります。
- 異なるVPNクライアントやポータル
- 個別の認証情報セット
- 固有のバスティオンホスト
- 異なるネットワークセグメンテーションモデル
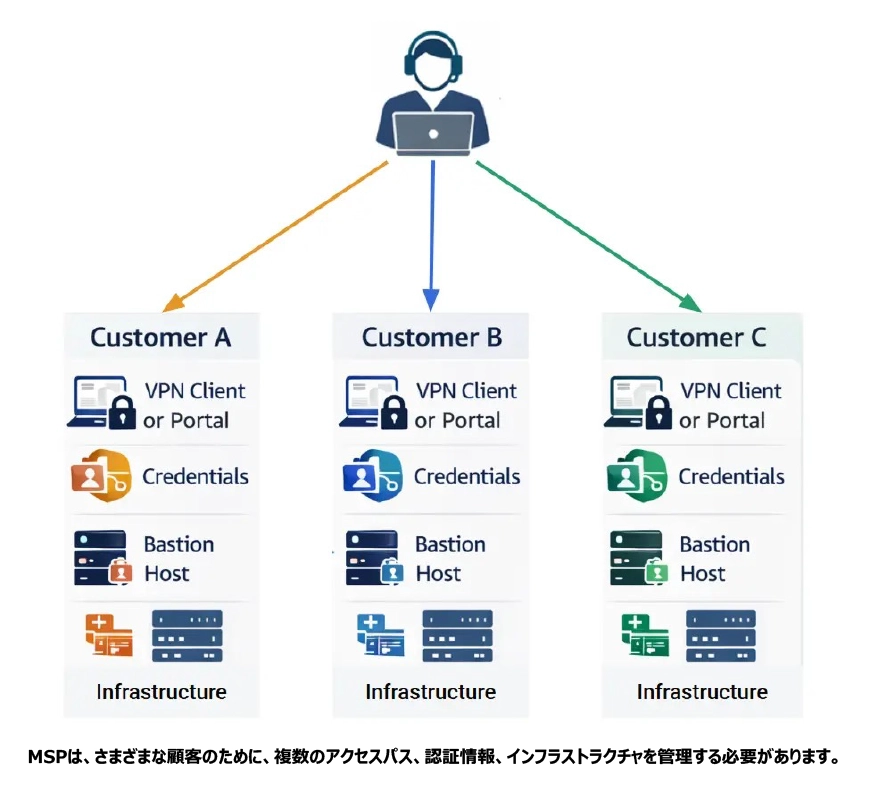
単一の障害をトラブルシューティングする際、影響を受けたデバイスに到達する前に、複数のアクセス層を経由しなければならない場合があります。これにより、対応時間が遅れ、インシデント発生時のアクセス障害の可能性が高まります。
運用負荷の増大
環境が拡大するにつれて、アクセスインフラの維持管理業務も増大します。MSPチームは、VPNゲートウェイの構築と保守、組織間のIDフェデレーションの管理、ジャンプホストインフラの監視、アクセス認証情報のローテーションやセキュリティ対策、接続性の問題の修正などを行う必要があります。
エンジニアが、インフラ自体の管理と同じくらいの時間をアクセスシステムの維持管理に費やしてしまうことは容易に起こり得ます。
サイト間で復旧の遅延が連鎖
単発のインシデントなら対処可能です。しかし、地域的なISPの障害や広範囲にわたるソフトウェアのバグにより、数十の顧客サイトがダウンしてしまう状況を想像してみてください。エンジニアは次のような対応を余儀なくされます。
- 環境をまたいだトラブルシューティング作業の優先順位付け
- すべての技術者を遠隔地に派遣する
- サードパーティの施設とのアクセス調整
- VPN接続の障害を回避する

管理対象サイトが増えるにつれ、こうした復旧の遅れは累積し、従来のリモートアクセスには限界があることが明らかになります。
運用コストは知らぬ間に増加する
年間でこれほど多くのサイトやインシデントを管理していると、その財務的影響は積み重なっていきます。実用的なリモートアクセスソリューションであっても、特にインシデントの対応に追加のトラブルシューティング時間、上級エンジニアへのエスカレーション、オンサイト復旧や出張費、SLA違反によるペナルティやクレジットが必要となる場合、それは事業運営における多大なコストとなってしまいます。
エンジニアリング業務が「消火活動」に変わる
ビジネスに与える最大の影響の一つは、エンジニアがネットワークの最適化、ジョブの自動化、セキュリティ強化の導入に注力できなくなり、かわりに運用上のトラブルの対応に追われるようになることです。戦略的な改善が、リモートアクセスの障害や事後対応的な復旧作業に後回しにされると、チームの生産性は低下します。
解決策:管理と本番環境の分離
この課題の解決には、リモートアクセスツールや監視ツールを追加導入する必要はありません。多くのMSPは一歩引いて、根本的なアーキテクチャの見直しに取り組んでいます。彼らは、適切な「Isolated Management Infrastructure(IMI)」を用いたアウト・オブ・バンド管理こそが、唯一の解決策であることに気づき始めています。
ネットワーク障害時でもアクセスを維持する
アウトオブバンドアーキテクチャは、本番ネットワークとは独立して動作する別の管理パスを導入します。エンジニアは、顧客のインフラを通じたVPN接続のみに依存するのではなく、復旧と運用制御のために特別に設計された専用の管理プレーンを通じてデバイスにアクセスできます。これには以下が含まれます。
- ネットワーク機器やその他のデバイスへの直接コンソールアクセス
- セカンダリ(第2次)およびターシャリ(第3次)WANリンクを使用した独立した接続
- 大規模な障害時でも到達可能な集中管理ゲートウェイ
この管理プレーンには、5G/セルラー、衛星(Starlinkなど)、セカンダリISP、その他のリンクを介してアクセス可能です。Nodegrid Serial Console Plusのような最新のシリアルコンソールサーバーには、多要素認証やゼロトラスト制御といったエンタープライズグレードのセキュリティ機能に加え、管理プレーンを脅威から完全に隔離する機能も備わっています。MSPは、広範囲な障害に対処している場合でも、活発なサイバー攻撃を受けている場合でも、常に制御を維持できます。
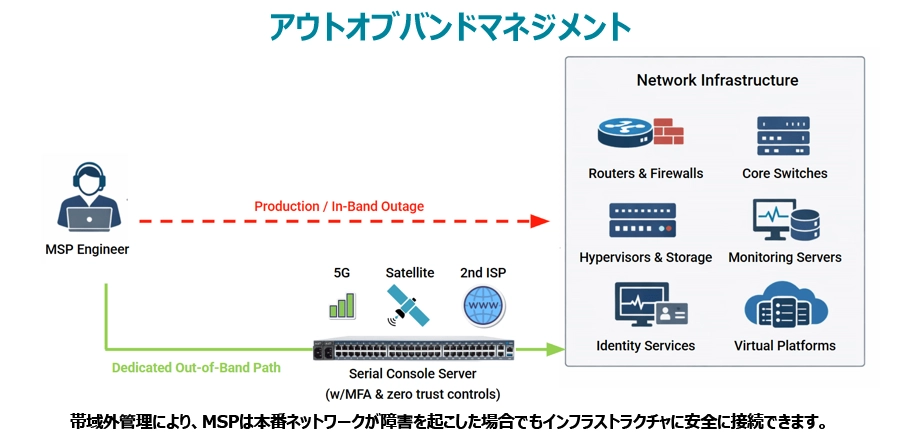
- ルーティングに障害が発生した場合でも、エンジニアはルーターのコンソールにアクセスできます。
- ファイアウォールポリシーによってアクセスがブロックされた場合でも、エンジニアはアウトオブバンド経路を通じてログインし、ルールを修正できます。
- WAN回線が完全にダウンした場合でも、携帯電話回線や衛星通信による接続を通じて環境にアクセスできます。
最大の違いは、管理用アクセスが本番ネットワークの状態に依存しなくなる点です。管理用アクセスは完全に独立したものとなり、常に利用可能になります。
多様な環境にわたる運用を簡素化
アウト・オブ・バンド管理は、従来のイン・バンド管理に伴う運用の複雑さを解消します。エンジニアは、顧客ごとに個別のVPN、認証情報、ジャンプホストなどを管理する必要がなくなります。サイト全体でのアクセスを一元化し、接続を標準化する単一の管理インフラを利用できるようになります。MSPチームは以下を実現できます。
- 顧客間で一貫したアクセスワークフローを維持する
- 一元化された認証および認可ポリシーを適用する
- 管理対象の全環境における管理活動を監査する
- インフラへのアクセスに必要なツールの数を削減
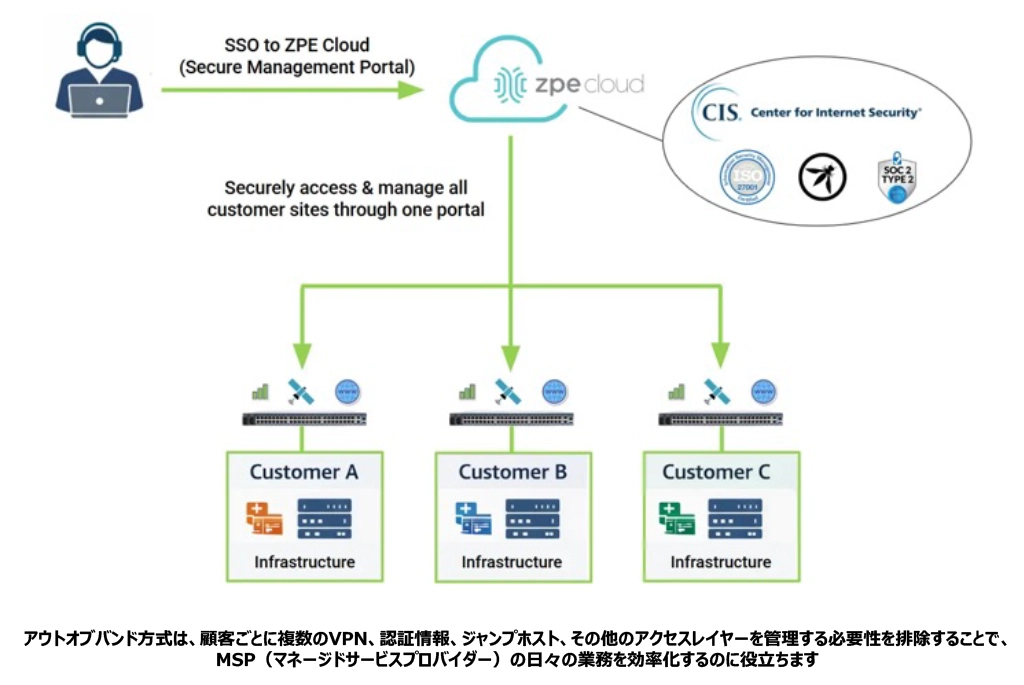
セキュアな管理ポータル「ZPE Cloud」をご利用のMSPの皆様は、一度ログインするだけで、クリック一つで顧客環境を切り替えることができます(その手軽さを紹介する動画はこちら)。これにより、日々の運用や障害復旧が簡素化され、チームの生産性向上につながります。
耐障害性の高いアクセスと一元管理の融合
最新のプラットフォームは、アウトオブバンド接続と一元的なオーケストレーションを組み合わせることで、運用上の耐障害性と安全なアクセス管理の両方を実現します。ZPEのNodegridのようなソリューションは、分散型インフラストラクチャ専用の管理ゲートウェイとして機能するように設計されています。この単一のプラットフォーム上で、MSPは以下のことが可能です。
- ネットワーク、コンピューティング、および全デバイスのスタックへのコンソールアクセスを常時利用可能に維持する
- 独立したセルラー回線やセカンダリ回線を介してリモートサイトに接続する
- ロールベースのアクセス制御とID統合を実施する
- 詳細なログ記録により、管理セッションを記録・監査する
- 地理的に分散した環境にまたがる数千台のデバイスを管理する
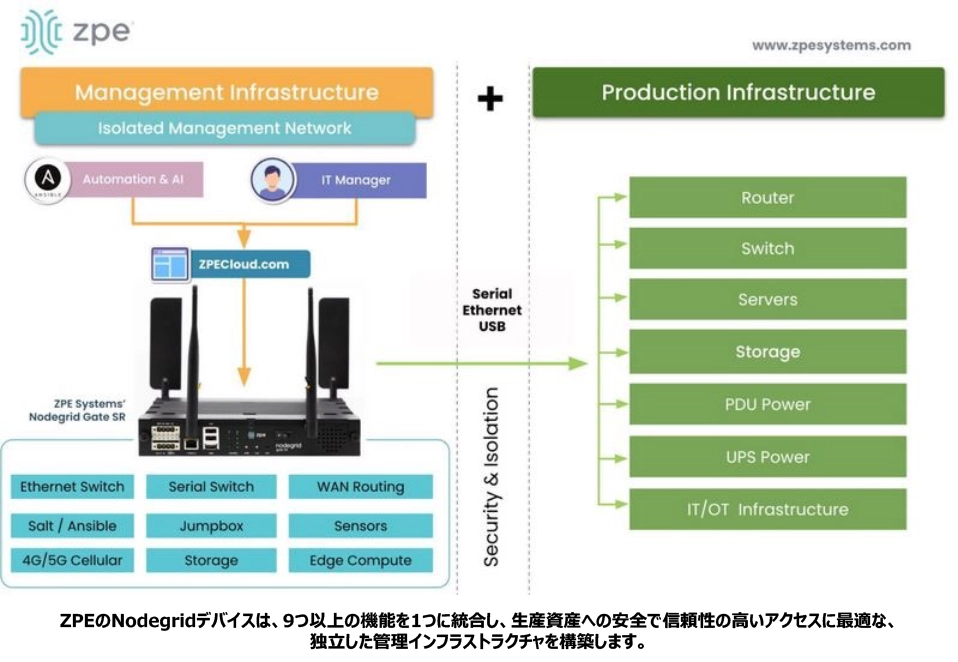
このアーキテクチャにより、本番ネットワークで障害が発生した場合でも利用可能な、独立した管理プレーンが効果的に構築されます。
事後対応ではなく、予測可能な復旧を実現
MSPにとって、このモデルの真の利点は運用面にあります。エンジニアが障害発生時でも常にインフラにアクセスできると分かっていれば、復旧はより迅速かつ一貫したものになります。トラブルシューティングを直ちに開始でき、設定ミスをリモートで修正でき、以前は現場への出動を必要としていたインシデントも、オペレーションセンターから解決できるようになります。
大規模な運用において、これらの改善は直接的に測定可能な成果につながります。
- 平均解決時間の短縮
- 現場対応回数の削減
- 運用コストの低減
- SLAパフォーマンスの向上
つまり、このアーキテクチャは、チームの運用手法を変革し、MSPがビジネスを効率的に成長させる方法を根本から変えるのです。
財務的影響の把握
多くのプロバイダーにとって、従来のリモートアクセスモデルの運用コストは、インシデントの発生頻度や、現場への対応や長時間のトラブルシューティングが必要となるケースを分析するまで、目に見えないままです。
MSPチームがこの影響を定量化できるよう、管理対象環境全体におけるダウンタイムの真のコストを見積もるためのシンプルなワークシートを作成しました。
このワークシートでは、インシデント件数、技術者の作業時間、出張対応コスト、SLA違反による違約金などの一般的な入力項目を順を追って入力することで、障害復旧にかかる年間財務的影響を算出します。
さらに、堅牢な管理インフラがこれらのコストを大幅に削減できることを示しています。今すぐダウンロードして、コストを分析し、アウトオブバンド導入による潜在的なROIを確認してください。