【エッジAI基礎 × eYs3D】ディープラーニングの「CNN」とは?


目次
1.はじめに
CNN(Convolutional Neural Network、畳み込みニューラルネットワーク)は、ディープラーニングの一種であり、特に画像認識の分野で広く利用されています。CNNは、画像データから特徴を抽出し、それを基に分類や認識を行うアルゴリズムです。画像のエッジやテクスチャなどの局所的な特徴を捉えることができるため、非常に高い精度で画像を解析することができます。CNNはその名の通り、人間の脳の神経回路を模倣したニューラルネットワークをベースに構築されています。
2.ニューラルネットワークの概要
先ほど述べたようにニューラルネットワークは、人間の脳の神経回路を模倣した計算モデルであり、機械学習の一種です。ニューラルネットワークは、入力データを処理し、出力を生成するために複数の層(レイヤー)を使用します。これらの層は、入力層・隠れ層・出力層から構成されます。各層のニューロンは、前の層のニューロンと接続され、重みとバイアスを持ちます。ニューラルネットワークは、これらの重みとバイアスを調整することで、データのパターンを自律的に学習します。特にCNNでは、画像の特徴を抽出するために、畳み込み層とプーリング層と呼ばれる特殊な層が用いられます。 これらの層については、後ほどご説明します。
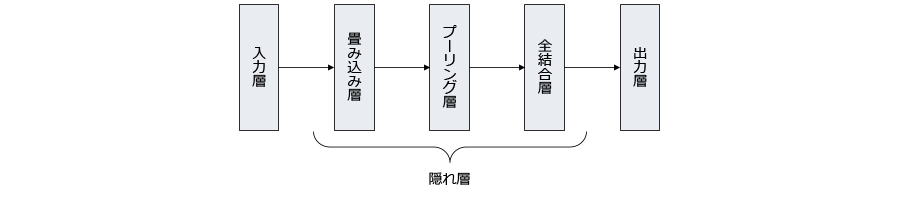
3.CNNの基本構造
CNNは主に以下の層から構成されています。隠れ層である畳み込み層・プーリング層・全結合層は複数回繰り返されることで、モデルがより複雑な特徴を学習できるようになります。
- 入力層:画像データを受け取る層です。
- 畳み込み層:入力画像に対してカーネル(フィルター)を適用し、畳み込みと呼ばれる演算によって特徴マップを生成します。
- プーリング層:畳み込み層で得られた特徴マップを縮小し、計算量を削減します。
- 全結合層:すべてのニューロンが前の層のすべてのニューロンと接続されており、最終的な分類を行います。
- 出力層:最終的な分類結果を出力する層です。
4.CNNのレイヤー概要
以下、手書き数字の文字認識を例にして、CNNの各レイヤーの概要をご説明します。
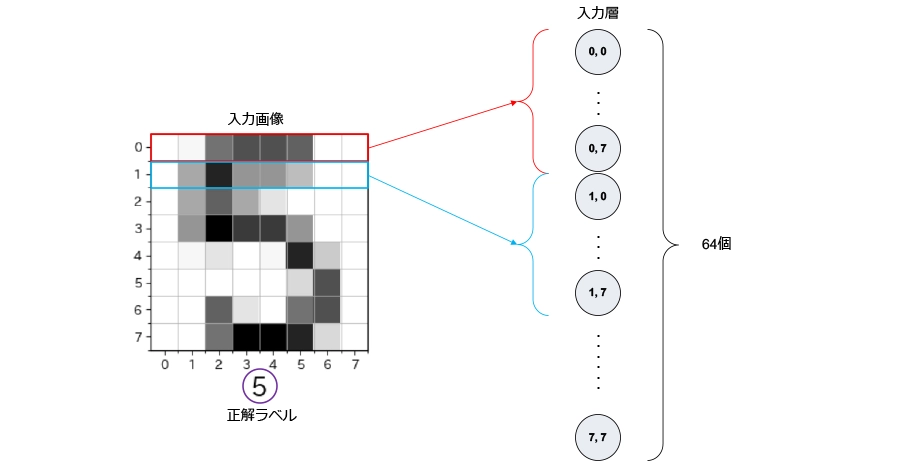
入力層
8×8ピクセルのグレースケール画像の場合、入力層には64個のニューロンが存在します。一行目のピクセル(赤)は(0, 0)から(0, 7)の8つのニューロン、二行目のピクセル(青)は(1, 0)から(1, 7)の8つのニューロンに対応します。
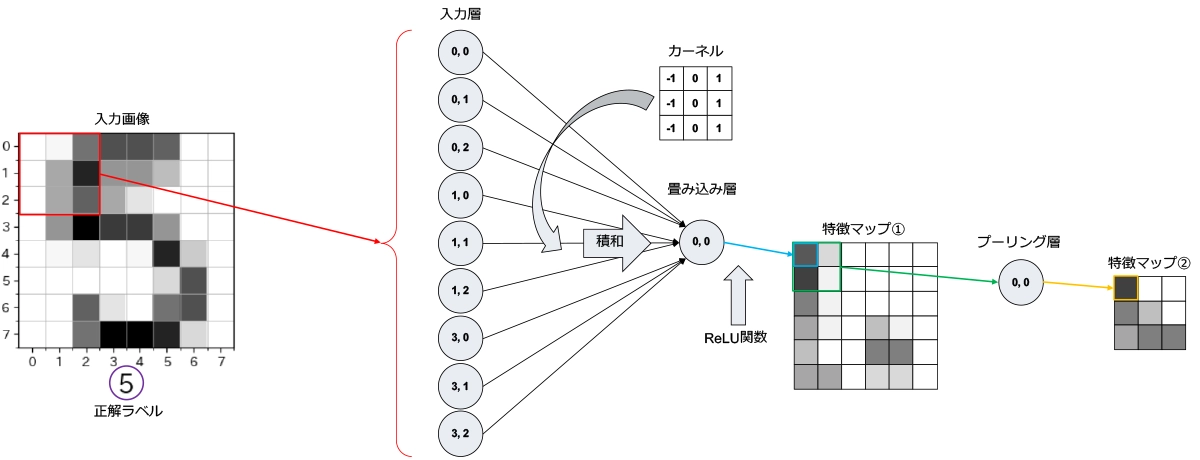
畳み込み層
3×3ピクセル(赤)を一つのまとまりとして扱います。これらの入力層のニューロンのデータに対して、3×3のカーネル(例)を適用します。同じ位置のピクセル同士を乗算し、得られた9つの値を加算することで、この赤い領域からは青の特徴が抽出されます。そして、赤で示した範囲を1ピクセルずつ移動して、同じカーネルによる積和演算を行います(畳み込み)。この時、加算結果が負の場合は0として扱います(ReLU関数)。今回のカーネルでは、縦線が強調されたような6×6の特徴マップ①が生成されます。
注:この例では、説明を分かりやすくするために、入力画像の周囲のピクセルをゼロデータで埋めていません(ゼロパディング)。そのため、出力される特徴マップのサイズは、入力画像のサイズよりも小さくなりますが、ゼロパディングを行うことでそれらは同じサイズになります。ゼロパディングは、画像の端の特徴をより効果的に抽出するために使用されます。
プーリング層
次に、得られた特徴マップを2×2の領域(緑)に分け、その中で最も大きい値を抽出します(橙)。緑で示した範囲を2つずつ移動して、他の2×2の領域にも適用すると、3×3の特徴マップ②が生成されます(最大プーリング)。これは、特徴マップの解像度を下げ、重要な情報を保持しながら計算量を削減するプーリング層の働きです。
全結合層
全結合層は隠れ層の最後に配置されます。この層では、すべての入力ニューロンが次の層のすべての出力ニューロンに接続されます。全結合層は、畳み込み層やプーリング層で抽出された特徴を基に、最終的な分類を行う役割を持ちます。0から9の数字を分類する場合、その特徴をもとに各数字に対するスコアを計算します。
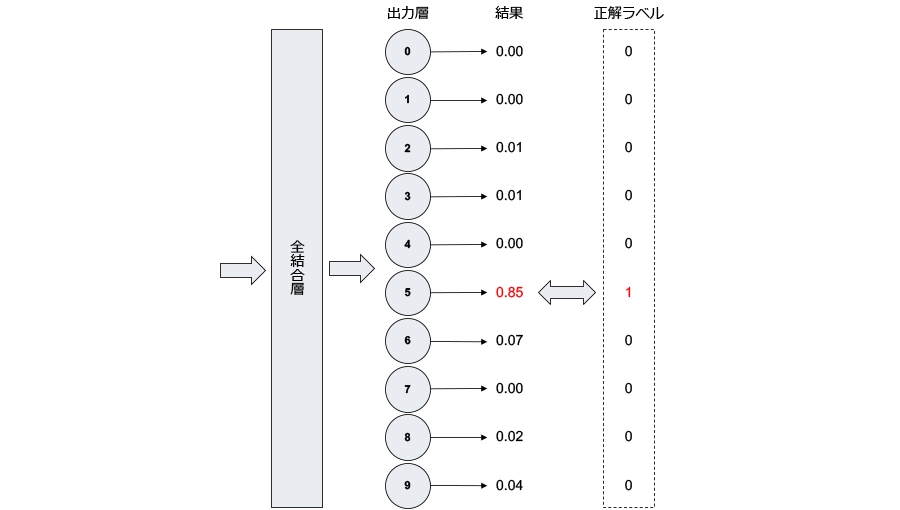
出力層
出力層には10個のニューロンが存在します。これらのニューロンには認識結果として確率値が入り、10個のニューロンの値を合計すると1になります(ソフトマックス関数)。また、数字の5を学習する場合、その正解ラベルは5番目の要素が1で、それ以外は0になります。学習の過程では、各ニューロンの出力と正解ラベルの誤差が小さくなるように、隠れ層のニューロンのパラメーターが調整されます(交差エントロピー)。一方、推論においては、出力層で得られた値が結果になります。
5.CNNの特徴・応用例・比較
CNNの特徴
CNNには以下のような特徴があります。
- 局所受容野:畳み込み層では、カーネルが画像の一部に対して適用されるため、局所的な特徴を捉えることができます。これにより、画像全体を一度に処理するのではなく、部分的に処理することが可能です。
- 重み共有:畳み込み層では、同じカーネルが画像全体に対して適用されるため、パラメーターの数を大幅に削減できます。これにより、計算効率が向上します。
- 移動不変性:プーリング層により、画像中の特徴が多少移動しても認識性能が維持されます。これにより、画像の位置やスケールの変化に対して、頑健なモデルが構築できます。
CNNの応用例
CNNは以下のような分野で用いられています。
- 画像分類:手書き数字の認識や一般物体認識(人・犬・猫など)などで広く利用されています。
- 物体検出:画像中の複数の物体を検出し、それぞれの位置とクラスを特定します。代表的な手法としてYOLOなどがあります。
- セグメンテーション:画像中の各ピクセルがどのクラスに属するかを予測します。医療画像解析や自動運転車の視覚システムなどで利用されています。
- スタイル変換:ある画像のスタイルを別の画像に適用します。例えば、写真を絵画風に変換するなどの応用があります。
CNNと他のディープラーニングモデルとの比較
各ディープラーニングモデルの特徴や得意分野は以下の通りです。

6.eCV5546のNPU
eYs3D社のエッジAI SoCのeCV5546には、以下の特徴を持つNPU(Neural Processing Unit)を内蔵しています。
- CNNの推論に特化
- 最大4.6 TOPS(1GHz動作時)
- PPU内蔵(Parallel Processing Unit、並列処理ユニット):PPUは、ToFやレーダーなどフィルター処理が必要なセンサーの前後処理を行い、CPUの負荷を軽減

eCV5546を用いたエッジAIプラットフォームXINK V2が提供されています。
7.まとめ
CNNの基本構造や特徴についてご紹介しましたが、いかがでしたか?CNNは画像認識に優れたディープラーニングモデルであり、eCV5546のNPUはそのCNNの推論に特化しています。NPUに求められるTOPS値はアプリケーションによって異なります。eCV5546のNPUが適する用途やデモについては、以下の記事をご覧ください。
関連商品
 eYs3D Microelectronics: 3DマシンビジョンとエッジAIで未来を拓く
eYs3D Microelectronics: 3DマシンビジョンとエッジAIで未来を拓く
 【AI: Computer Vision】eYs3D XINKデモを動かしてみた
【AI: Computer Vision】eYs3D XINKデモを動かしてみた

